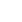
庭审实况复盘-AIPPI全球示范庭审胜诉案(“AI数字人”发明专利侵权案)
-案情梗概-
南京某AI企业(原告)起诉杭州某科技公司(被告)的”AI数字人”产品所使用的技术方案侵犯其"音频驱动口型生成方法"发明专利,索赔50万元。原告主张被告“AI数字人”产品采用的技术方案全面覆盖其专利权利要求1,核心争议聚焦于动态视频口型同步技术是否落入专利保护范围。

(涉案专利权利要求1要点)
-第一部分:原告诉请和被告答辩-
原告诉请(诉状共9页)简要概况:被告侵涉案专利权1,要求被告停止侵权,索赔50W。事实与理由:略。
被告简要答辩:
1.被告的技术方案采用的是现有技术,不侵权。
2.被告的技术方案没有落入原告专利的保护范围,不侵权。
3.被告认为原告提起本案诉讼属于恶意诉讼,保留向原告提起反诉的权利。
-第二部分:双方举证质证-
原告举证:

被告质证:
证据1-2,三性认可。
证据3,三性认可。证明目的不认可,关于该份证据的主要内容:为一自媒体主播对被告产品的体验讲解视频,主要分为三步:1.用户录制5-10分钟的说话视频,2.用户录制15秒左右的静默视频,3用户上传目标语音,使步骤1中的视频说出的话和对应的口型与步骤3的语音一致)。
通过该证据可见,被告已经对自己的“AI数字人”作出了详细的讲解演示介绍。原告成立于2017年8月8日,其名下可查公开专利数量近200件,原告应当具有一定的专利法律的认知能力,知道专利侵权判定的基本原则和方法。在提起本次发明专利侵权纠纷时,应当对自己所申请专利的技术方案有基本准确的认知,对专利的保护范围有准确的理解的,稍加审慎的评估指控被告侵权的初步证据。应当能毫无疑义的得出该技术方案没有落入专利的保护范围,因此该份证据可佐证,原告提起诉讼时,未尽到合理的审慎义务,违背基本的法律和商业道德,属于恶意诉讼。
证据4,真实性合法性认可,关联性不认可,被告在产品上线运营初期,曾购买原告的一套产品用于对标竞品研究,且被告采购的原告产品,也不是涉案专利对应的产品。
被告举证:
原告质证:略
-第三部分:法庭归纳争议焦点-
争议焦点1:被告技术方案是否落入原告专利保护范围
争议焦点2:被告现有技术抗辩是否成立
争议焦点3:如果被告侵权,三被告是否构成共同侵权,应当承担的赔偿责任。
-第四部分:法庭事实调查实质与辩论合并(含法庭发问)-
原告侵权比对意见
原告主张“特征提取模块、编码器模块、合成模块、数据处理模块、和解码器模块”相同;
预处理模块则主张等同,原告认为:被告的技术方案需要用户录制“10-15秒静默真人视频”等同专利“根据样本图像生成预设时长的静默视频,并将所述静默视频处理为样本图像数据……”。
法官:争议焦点1,是否落入权1保护范围?被告发言。
被告侵权比对意见
被告:在技术侵权比对前,应当先根据涉案专利的文本,确认专利权利要求技术方案的保护边界。进而比对被控侵权方案是否落入保护范围。被告结合PPT及视频演示,说明对专利保护范围的理解AI数字人技术背景介绍
数字人是2018年后逐步兴起的一项技术,目前主要有三种技术路线方案:
1.一种3D动画数字人,特点 :3D建模,目前动作较为僵硬,效果较差
2.一种图片数字人,通过替代静态图片的嘴型图像,生成与音频对应的嘴型动态视频。特点:目标视频的人物图像,除了嘴型随着音频变化,人物姿态、头像轮廓静态不动,数字人说话时的牙齿和嘴巴不够自然逼真。
3.一种视频数字人:以wav2lip算法为代表的数字人模型,可以对动态视频说话的面部进行口型同步。特点:算法复杂,对训练数据要求高,算力需求大,生成效果更逼真。
|
3D动画数字人 |
|
|
 |
这三种AI数字人的产品适用场景,虚拟效果不同,技术路线方案之间存在巨大的区别。

涉案专利的技术方案是半静态嘴型同步数字人(图片数字人),主要依据如下:
1.涉案专利在审查意见答复意见的第5页,专利权人强调:涉案专利的静默视频是基于一张样本图像,每一帧图像均为同一样本图像。(涉案专利申请公开文本的0042,对应授权文本的0076)


2.[0053]-[0054]所述:涉案专利解决的技术问题是“以口型动作视频作为通用样本数据(注:即为视频数字人技术方案)…需要大量样本数据,获取样本数据的过程十分困难,”即相当于专利在背景技术中排除了将“视频数字人”技术方案纳入保护范围。

3.除此以外,在说明书的[0080]-[0082],[00116]-[0120]中的相关记载也可佐证,不展开赘述。



从涉案专利说明书相关记载可知,涉案专利对“视频”和“图像”作了区分。特别是在AI数字人领域,其音频驱动人物口型的实现路径、效果、难度上具有重大区别(wav2lip论文也指出:适用于静态图像的模型无法准确的应用在视频内容中的各种嘴唇形状中)

因此“视频”和“图像”属于不同的,不构成等同的技术特征。
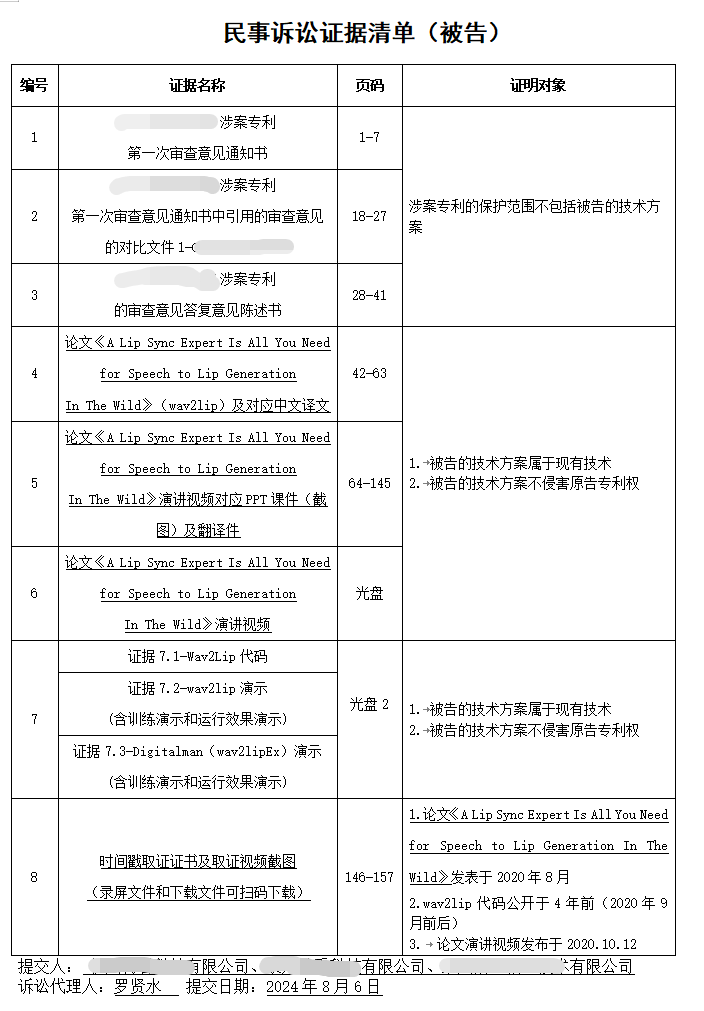
被告的技术方案需要用户录制动态的“说话视频”和“不说话视频”参与训练,对目标用户的动态说话视频进行目标音频驱动替换口型,形成新的AI数字人视频。

被控侵权的数字人技术方案包括“特征提取模块、编码器模块”等这些概括性的模块表述特征。但从整体的技术方案上看,涉案专利描述的是图片数字人,被告技术方案是视频数字人,各个模块都有显著不同,被告重点说明,被告技术方案特征提取模块及预处理模块与涉案专利的差异。

特征提取模块里有“目标图像”和“目标动态图像”两个技术特征的限定解释,被告已经在前面就《有关明确涉案专利权1保护范围》中详细阐述,专利中的“目标图像”指的是一张静态的图片。
“目标动态图像”指的是:静态图片(目标图像)+口型动作。
而被告的技术方案在特征提取模块提取的是视频的动态视频帧,动态视频的每一视频帧人物的姿态,人物头部轮廓是不同的。两者即不相同,也不等同。
法官:被告具体说明一下,为什么认为两者既不相同也不等同?
|
技术特征 |
涉案专利方案 |
被告技术方案 |
|
输入数据类型 |
单张静态图片 |
动态视频序列(说话/静默视频) |
|
样本生成方式 |
图片生成预设时长静默视频 |
提取真人录制的动态视频关键帧 |
|
算法处理逻辑 |
基于坐标定位的静态口型替换 |
时空特征建模的动态唇部同步 |
|
训练数据需求 |
低样本量(依赖辅助数据替代) |
高样本量(需真实说话视频) |
专利的技术方案:一张静态图片的数据仅需提取一次,在算法程序中进行存储-标记-推理-调用处理;而动态视频帧的数据量和后续的处理和算法都将不一样。
静态目标图像的每个数位点可以视为坐标,根据相对坐标位置,指示出目标图像的嘴巴位置,从而替换语音生成的口型图像,形成目标动态图像。仅需要一次嘴巴位置定位,即可完成后续的替换口型的定位,算法简单,所需训练量小,效率高。
被告方案是动态视频的视频帧。动态视频的每一视频帧人物的姿态,人物头部轮廓是不同的(被告技术方案能接受目标人物立最大30°转动脸部的视频,模特视频拍摄指引,闭口视频让微微晃动头部,说话视频带有大量动作)。根据模型算法,综合确定每个视频帧嘴巴的位置和角度对目标语音驱动的口型位置进行替换。
就像专利在[0053]背景技术中提到的,以口型动作视频作为通用样本数据,通过学习口型动作视频中的口型变化与音频的关系,进而使得模型能够实现音频驱动口型。就导致训练模型需要大量的样本数据,获取样本数据的过程十分困难。
视频数字人在样本数据获取成本和呈现的数字人逼真效果的技术路线上,与专利是两条不同技术路线的取舍。

编码器模块、合成模块、数据处理模块和解码器模块是对特征提取模块提取处理的图像特征和音频特征进行的后续处理,因在特征提取模块提取的“动态视频帧”与专利的“目标图像”不相同也不等同,因此后续的编码器模块、合成模块、数据处理模块和解码器模块的技术手段和实现的功能也不相同且不等同。
如果被告采用专利特征提取模块的技术方案提取动态视频帧,后续采用与涉案专利相同的技术方案,在目标人物的头和脸姿态,稍微动态变化时,替换嘴型的贴图就会产生移位失真不可用。而被告的AI数字人并没有出现这样的移位失真问题。正是因为被告的编码器模块、和合成模块、数据处理模块和解码器模块与专利的相应模块不相同也不等同。
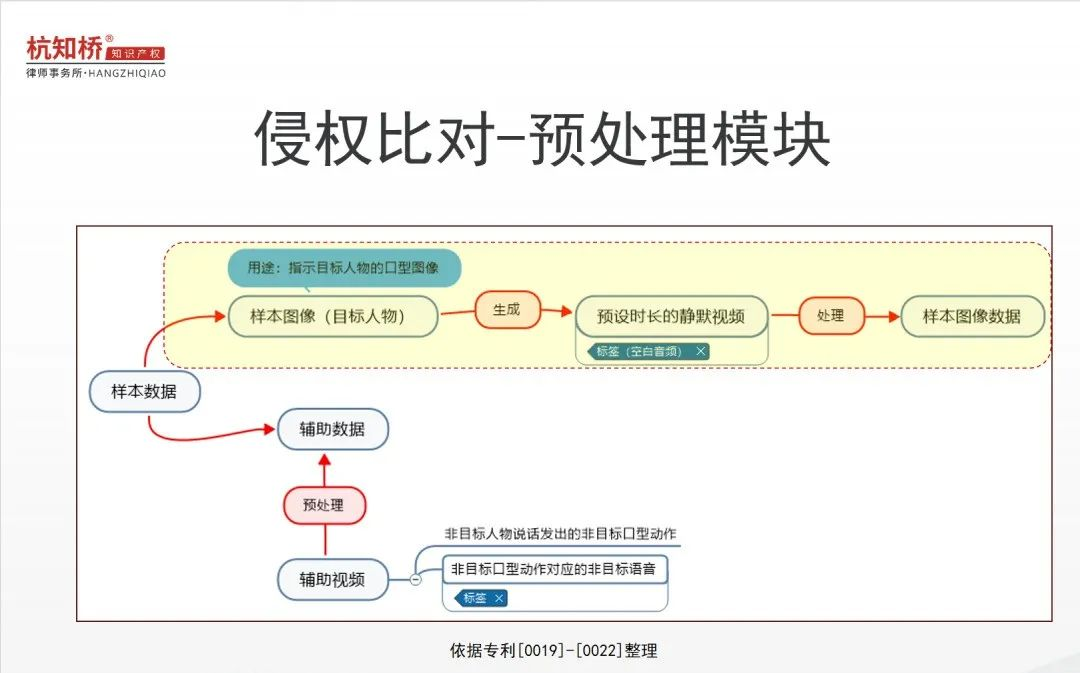
被告根据专利说明书,被告整理了一份说明专利的预处理模块的流程图,被告技术方案和专利所述的预处理模块的区别主要体现“在所述模型的训练过程中根据样本图像生成预设时长的静默视频,并将所述静默视频处理为样本图像数据……所述样本图像用于指示目标人物的口型图像”。
被控侵权方案的预处理模块不含有“根据样本图像生成预设时长的静默视频,并将所述静默视频处理为样本图像数据”步骤。法院技术勘验时,被告也演示过,被告的模型无法上传图片照片进行训练。

关于专利的“样本图像”,可结合涉案专利在审查意见答复意见的第5页、说明书[0075]-[0076]、[0080]-[0083]进行理解:涉案专利权1中的“静默视频”是基于一张样本图像,每一帧图像均为同一样本图像。(预设时长的视频中,样本图像始终相同)
被控侵权方案的预处理模块遵循的是“输入视频-提取视频帧-提取人脸关键点”步骤,此处视频包括录制的说话视频和静默视频。
被告的技术方案中,“录制真人没有声音的静默视频样本”并不是预设时长,且有微微晃头的姿态变化,其目的在于:收集目标真人不说话时的口型静默图像,训练AI模型学习生成更准确自然的目标数字人在不说话时的口型图像。不能等同专利的“根据样本图像生成预设时长的静默视频”。
被告技术方案是直接对目标人物的动态视频帧进行口型算法的计算替换,用户预先录制的自然说话的动态视频在目标语音的时长内循环播放,音频驱动生成对应变化口型。
法官:被告回应一下,你方认为两者不构成等同的主要依据是什么?

从等同特征的比对原则:三基本(手段,功能,效果基本相同)+容易想到(不需要创造性劳动)
两者手段——不一样:处理图片和视频的技术逻辑和区别显著
两者功能——不一样:专利技术方案运用“样本图像”,通过辅助数据替换的方式,达到音频驱动口型的目的,减小训练过程中需要的样本数据的量级。指的是不需要用户提供说话的视频提供音频和口型数据,节约样本数据量级。被告的技术方案必须录制用户说话和静默的视频,是用于提供音频和口型数据进行模型训练)
两者效果——不一样:从训练样本数据需求量,被告技术方案存在专利的[0053]记载的背景技术方案的技术问题“需要大量样本数据进行训练”)。
如果按照原告主张的被告“录制真人没有声音的静默视频样本”的目的解释为“是为了根据样本视频生成预设时长的静默视频”,想要用“视频”替换专利中的“图像”,在AI数字人领域,需要克服技术难题,付出巨大的创造性劳动,形成一个全新的技术方案。

两者从发明目的和技术应用场景来说,涉案专利为了实现“减小训练过程中需要的样本数据的量级”的目的,用户仅需提供图像照片,由辅助数据进行模型口型生成的训练,实现目标音频驱动目标图像生成对应口型图像的目的。会带来一个显著的技术缺陷:
专利技术方案——音频驱动图像:因为没有目标人物说话时的牙齿和嘴巴的图像信息,目标人物的嘴巴图形是AI模型依据辅助数据的训练凭空推理的,没有目标人物的唇部和牙齿的参考图像数据。生成AI数字人说话时的牙齿和嘴巴会很不自然。
被控侵权方案为了实现逼真的技术效果,需要让用户上传说话视频和静默视频用于训练。会需要更大量级的样本数据,但有一个更好的技术效果:
音频驱动动态视频的AI数字人:牙齿和嘴巴更自然逼真。
因为被告的技术方案采用了wav2lip的技术路线和代码逻辑:用了3-10分钟目标人物的说话的视频,包含牙齿和嘴部的各个姿态的图像信息,AI模型通过这些数据能够学会这个人在不同姿态下说不同的话应该是什么样子。
被告的技术效果,仅用目标人物的图像照片无法实现。且不能通过专利记载的用一个目标图像加辅助数据的训练方式,简单的用视频替换图像进行。因为专利技术方案只训练了目标人物一张图片一个姿态下的说话方式,没办法适应动态视频人物在不同姿态下的说话方式。
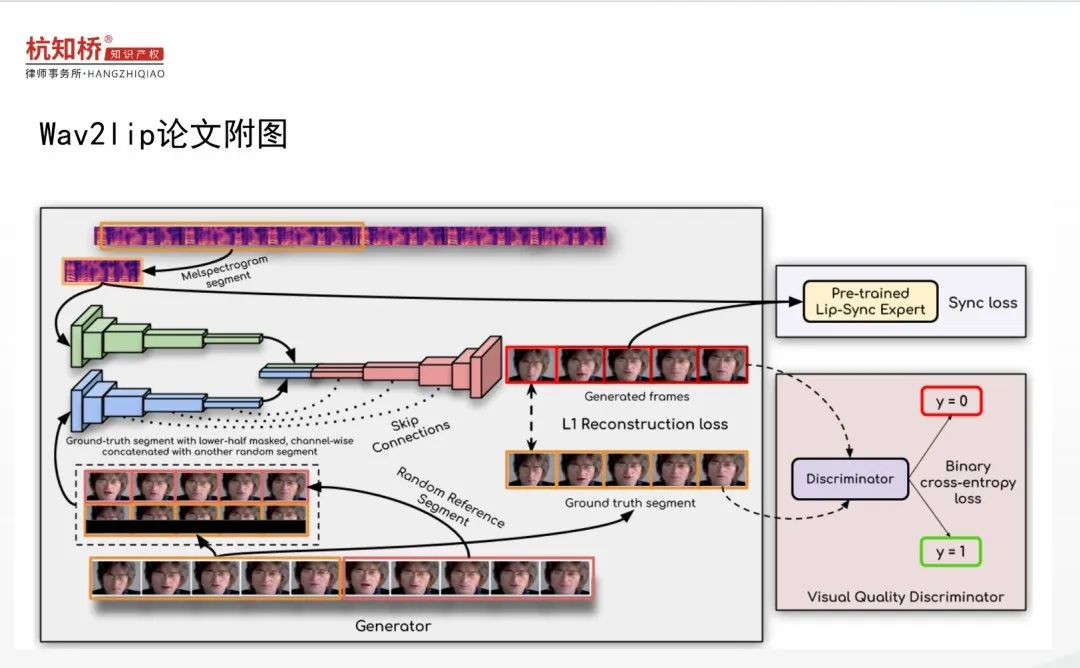
技术勘验时,被告已演示被告代码及wav2lip代码运行的情况,在预处理模块和特征提取模块均遵循的是“输入视频-提取视频帧-提取人脸关键点”技术步骤,被告技术方案运用的是wav2lip代码相同的技术方案,即上传动态视频进行预处理及模型训练。图像数据的获取均是采用“输入视频-提取视频帧-提取人脸关键点”的技术方案。没有“使用样本图像生成预设时长的静默视频,并将所述静默视频处理为样本图像数据;”的技术步骤。
结合wav2lip论文理解wav2lip代码的技术方案,如论文附图所示,上部分展示的音频的特征提取,下部分展示的视频的特征提取,在中间青色、蓝色、粉色模块,分别展示的是编码-合成-数据处理-解码模块。被告也提供了wav2lip的完整代码,包含上述模块,技术勘验时也向法庭演示被告代码及wav2lip代码运行的功能效果一致。
法官:原告认为被告的源代码与wav2lip不一样,因此现有技术不成立,被告什么意见?
我方技术方案对wav2lip代码的每一个模块都做了优化改进,如音频特征提取网络,我们使用更加先进的函数处理方法来去掉语言之间的差异,使得数字人支持不同国家的语言等等。在以专利的技术特征体现为各个模块的功能及彼此之间的逻辑关系,虽然被告的模型代码与wav2lip代码不完全相同,但各模块的功能及内在的逻辑保留Wav2lip整体的技术逻辑,因此被告的现有技术抗辩仍成立。
我方认为,前述特征的区别论述,已足以的得出被告技术方案不侵权的结论。其他特征的比对,在庭前会议已有一一阐述,且被告向法庭提交了书面比对意见,不再赘述展开。
调查结束后,被告补充意见:
通过整个庭审过程,我方从整体技术方案、逐个技术特征的比对,已全面的论述说明了被告AI数字人技术方案不侵权的观点。而原告作为专利权人,在取证提交证据3时,稍作审慎的评估,就应知或明知本案被告不侵害其专利权。且基于wav2lip论文的含金量和影响力,wav2lip论文的演示代码也随论文公开,原告作为本领域从业者,不可能不知道wav2lip论文。
原告作为本领域从业者,基于对wav2lip技术的基本了解,将自己的专利、被告的数字人产品、wav2lip技术稍作审慎的评估,原告也应当能得出被告的技术方案路线与wav2lip基本吻合。因此,我方认为原告提起本案诉讼的动机和目的并不是为了维权,
未尽到合理的审慎义务,违背基本的法律和商业道德,构成恶意诉讼及不正当竞争,请求法庭驳回原告诉请。同时被告保留向原告提起反诉的权利。
后记
本案胜诉印证:技术类案件的法庭对抗,本质上是技术事实的法律翻译竞赛,用专业打败专业,用技术逻辑破解法律迷局。律师既要成为技术的解读者,更要成为技术语言的转译者——这正是数字时代法律人的核心竞争力。





